DNS یک دیتابیس توزیعشده، سلسه مراتبی و پویا است که وظیفهی فراهم کردن اطلاعاتی در رابطه با یک دامنه و آدرسهای IP مرتبط با آن را بر عهده دارد. در این مطلب سعی میکنیم علاوهبر مرور تاریخچه DNS، مشکلات امنیتی آن و دلیل بهوجود آمدن راهکار DNSSEC را شرح دهیم.
تاریخچه DNS
زمانیکه مفهوم اینترنت به گستردگی امروز نبود، سیستمها برای برقراری ارتباط با یکدیگر، از آدرس IP استفاده میکردند. با رشد اینترنت و افزایش تعداد دستگاههایی که مجهز به اینترنت بودند، تصمیم بر آن شد که سیستمها با نامهایشان یکدیگر را فرا بخوانند. به همین دلیل به مکانیزمی برای مشخص کردن آدرس IP متناظر با هر نام نیاز بود.
نخستین راهحلی که برای این مشکل مطرح شد، استفاده از فایلی با نام host بود. در این فایل آدرس IP متناظر با هر نام درج شده و به هر سیستمی که قصد ارتباط با سایر سیستمها با نام را داشت، منتقل میشد. اما با گستردهتر شدن دنیای اینترنت و اضافه شدن میلیونها دستگاه به این ساختار، در عمل استفاده از فایل host و انتقال آن به هر سیستم، کاری ناممکن بود. همین عامل سبب معرفی سرویسی با نام Domain Name Service (DNS) شد.
عملکرد DNS
در DNS، اطلاعات مربوط به یک دامنه و آدرسهای IP مرتبط با آن بهوسیلهی Resource Recordها مشخص میشوند که انواع مختلفی دارند و مشهورترین آنها رکورد A، رکورد MX، رکورد AAAA و رکورد NS هستند. با ساخت یک دامنه، برای آن یک Zone ساخته میشود که RRهای مرتبط با آن در فایلی با نام DNS zone file که یک فایل متنی ساده است، ذخیره میشوند. پس بهشکل خلاصه، وظیفهی DNS، نگهداری و فراهم کردن فایل DNS zone است.
آدرسهای DNS از چند Label ساخته میشوند که هر Label مشخصکنندهی سلسله مراتبی است که بهترتیب باید به سراغ آنها رفت. این Labelها از راست به چپ بررسی میشوند. برای نمونه نشانی .www.example.com دارای چهار Label است؛ “www“ که در این سلسله مراتب leaf بهشمار میآید،“example” که یک دامنه است، “com“ که یک TLD یا Top Level Domain است و درنهایت “.” که نشاندهندهی Root Server است.
زمانیکه در مرورگر خود نشانی www.example.com را وارد میکنید، در نخستین گام سیستمعامل Cache خود را برای یافتن آدرس IP متناظر با آن بررسی میکند. اگر هیچ آدرس IP پیدا نکند، recursive query را بهسمت Recursive Resolver ارسال میکند.
در DNS از دو نوع query استفاده میشود. Recursive و iterative. تفاوت این دو query عبارت است از:
- یک recursive query حتمن باید با ارسال یک Response پاسخ داده شود.
- iterative query به دریافت Response نیاز ندارد.
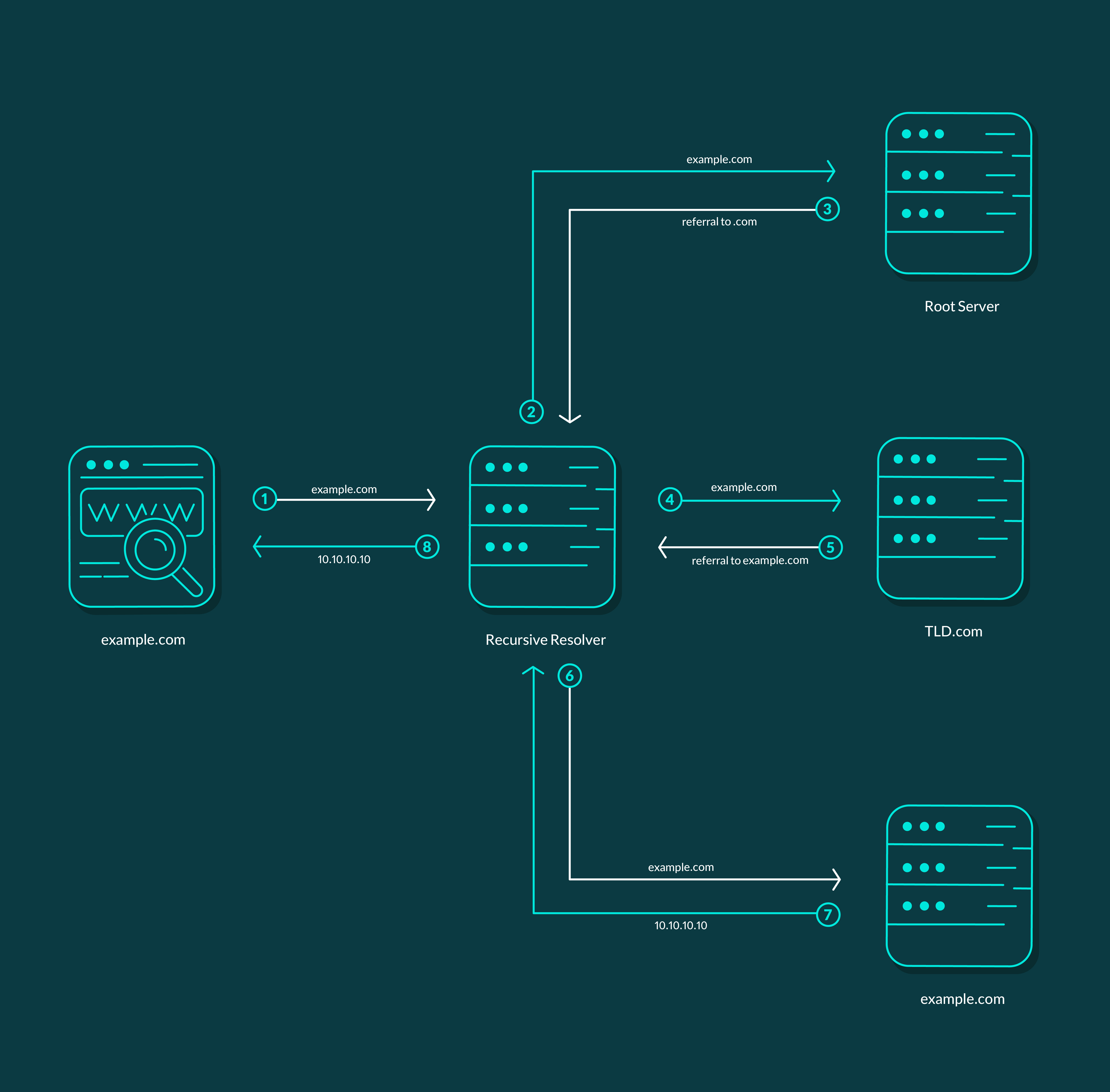
Recursive resolver میتواند DNS سرور فراهم شده بهوسیلهی ISP یا هر name server دیگری باشد که از سایر DNS سرورهایی که میتوانند در رابطه با آدرس IP دامنهی www.example.com پاسخ دهند، آگاهی دارد. Recursive Resolver با دریافت query از سمت مرورگر، ابتدا Cache خود را برای یافتن آدرس IP متناظر با آن بررسی میکند. اگر آدرسی پیدا نکند، با بررسی labelهای دامنهی www.example.com. از راست به چپ (نخستین برچسب . است) متوجه میشود اولین مکانی که برای پیدا کردن آدرس IP مربوطه باید به سراغ آن برود Root Server است.
اکنون سیزده Root Server در سراسر دنیا وجود دارند که دربردارندهی اطلاعات DNS مربوط به Top Level Domainها یا TLDها هستند. TLDها در واقع دامنههایی مانند .com، .org و… هستند. پس Recursive Resolver با ارسال یک iterative query از Root Server در رابطه با TLD .com سوال میکند و Root Server نیز در پاسخ، برای آن آدرس IP مربوط به TLD .com را ارسال میکند.
در گام بعد Recursive Resolver یک iterative request برای TLD که آدرس IP آن را از Root Server دریافت کرده است، ارسال میکند و در رابطه با example.com میپرسد. TLDها، DNS serverهایی هستند که اطلاعات DNS مربوط به زیردامنههای خود را نگهداری میکنند (در اینجا TLD .com دارندهی اطلاعات example.com است). TLD با دریافت درخواست، آدرس IP مربوط به example.com را برای Recursive Resolver ارسال میکند.
در مرحلهی بعد Recursive Resolver با ارسال یک iterative query برای example.com، آدرس IP متعلق به رکورد www.example.com را خواستار میشود. example.com نیز در پاسخ آدرس IP مربوط به رکورد www.example.com را برای Recursive Resolver ارسال میکند. درنهایت، Recursive Resolver که به آدرس IP مربوط به www.example.com دست یافته، آن را برای مرورگر ارسال میکند و صفحهی مربوط به این دامنه در مرورگر (البته با چشمپوشی از چند مرحلهی دیگر که ارتباطی با DNS ندارند) باز میشود. تمام این اتفاقات در کمتر از چند ثانیه رخ میدهند.
تصویر زیر بیانگر مراحلی است که گفته شد.
حملهی DNS Spoofing
در ابتدای معرفی DNS هیچ تصوری از ایجاد مشکلات امنیتی برای این سرویس محبوب نبود. البته این موضوع برای تمام سرویسها و پروتکلهایی که در ابتدای دههی ۱۹۸۰ میلادی معرفی میشدند، صدق میکرد. همین موضوع سبب شد تا آسیبهای امنیتی جدی برای DNS ایجاد شوند.
مسایل امنیتی DNS بهطور کلی در دستههای زیر قرار میگیرند:
- استفاده از reverse DNS برای جعل هویت کاربران
- خطاهای نرمافزاری (مانند سرریز بافر و …)
- رمزنگاری بد (مانند توالیهای پیشبینیپذیر و …)
- نشت اطلاعات (مانند دادههای نامعتبر یا افشای محتویات Cache)
- قرار دادن دادههای نامناسب در Cache یا در اصطلاح Cache poisoning
نخستین مشکل امنیتی که در DNS کشف شد، Cache Poisoning بود که از آن با نام DNS Spoofing نیز یاد میشود. DNS Cache Poisoning زمانی اتفاق میافتد که سرور DNS پایین دست (Recursive Resolver)، دادهها یا IP نادرستی را ارسال کند. در این حمله مهاجم با سمی کردن Cache سرور DNS پاییندست، سبب میشود که این DNS سرور در مقابل درخواستهایی که دریافت میکند، پاسخهای اشتباه و مورد دلخواه مهاجم را ارسال کند.
برای درک بهتر این حمله، تصویر زیر را در نظر بگیرید. در این تصویر قالب قدیمی پیامی حاوی دادههای DNS نشان داده شده که در آن، فیلدهای مهم مورد استفاده در حملهی Cache poisoning با رنگ آبی کم رنگ متمایز شدهاند.
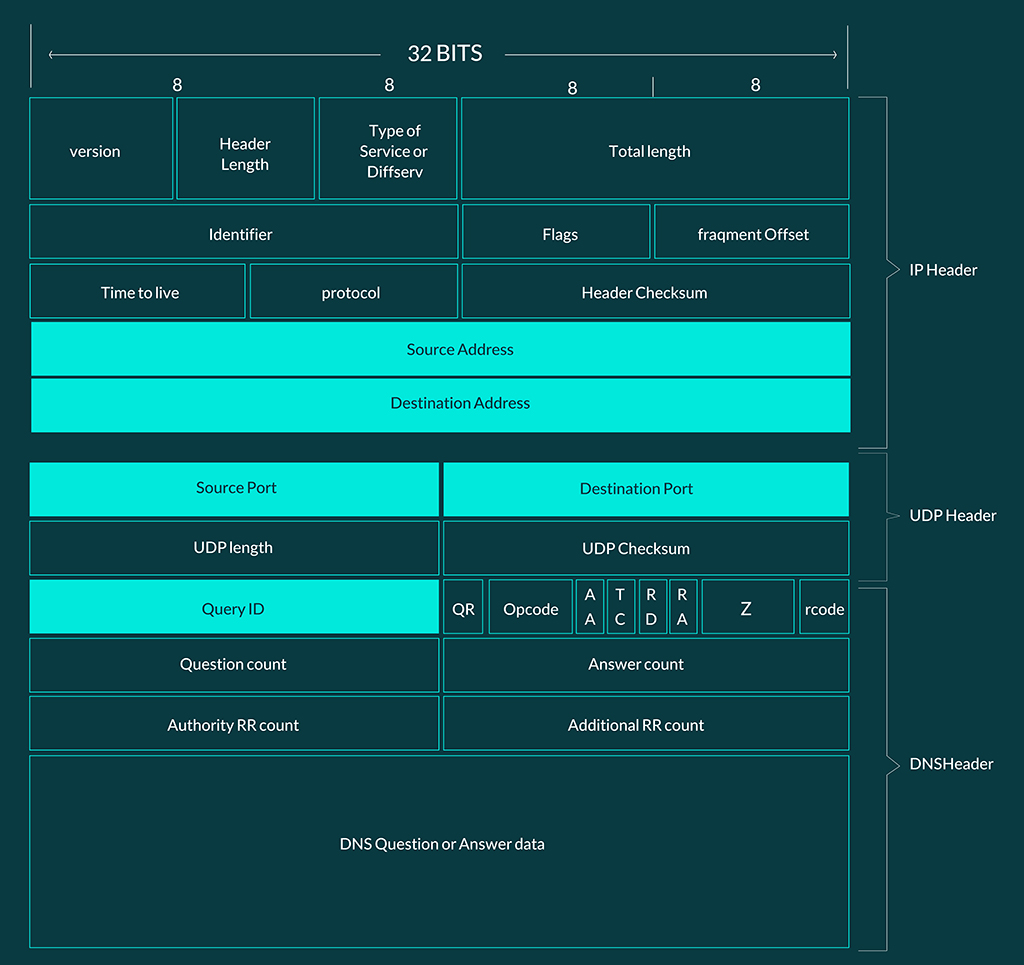
پایه و اساس این حمله بر دو موضوع استوار بود؛ نخست آن که در آن زمان، سرورهای DNS برای هر Query که تولید میکردند در فیلد Query ID (QID) (یا Transaction ID که از آن برای رهگیری queryها و responseهای آنها استفاده میشود) مقداری عددی قرار میدادند که بهازای هر پیام جدید، به این مقدار یک واحد اضافه میشد. به بیان دیگر، شماره QIDها یک رشته از اعداد متوالی بودند، پس با بهدست آوردن یک QID ،QID پیام بعدی بهراحتی حدس زده میشد.
مورد دوم آنکه DNS از UDP استفاده میکرد. بههمین دلیل، زمان ارسال یک Query روی یک پورت UDP، منتظر دریافت پاسخ مربوط به آن، از روی همان پورت میماند و بهمحض دریافت نخستین پاسخ درست، پاسخ پذیرفته میشد و سایر پیامها رد میشدند.
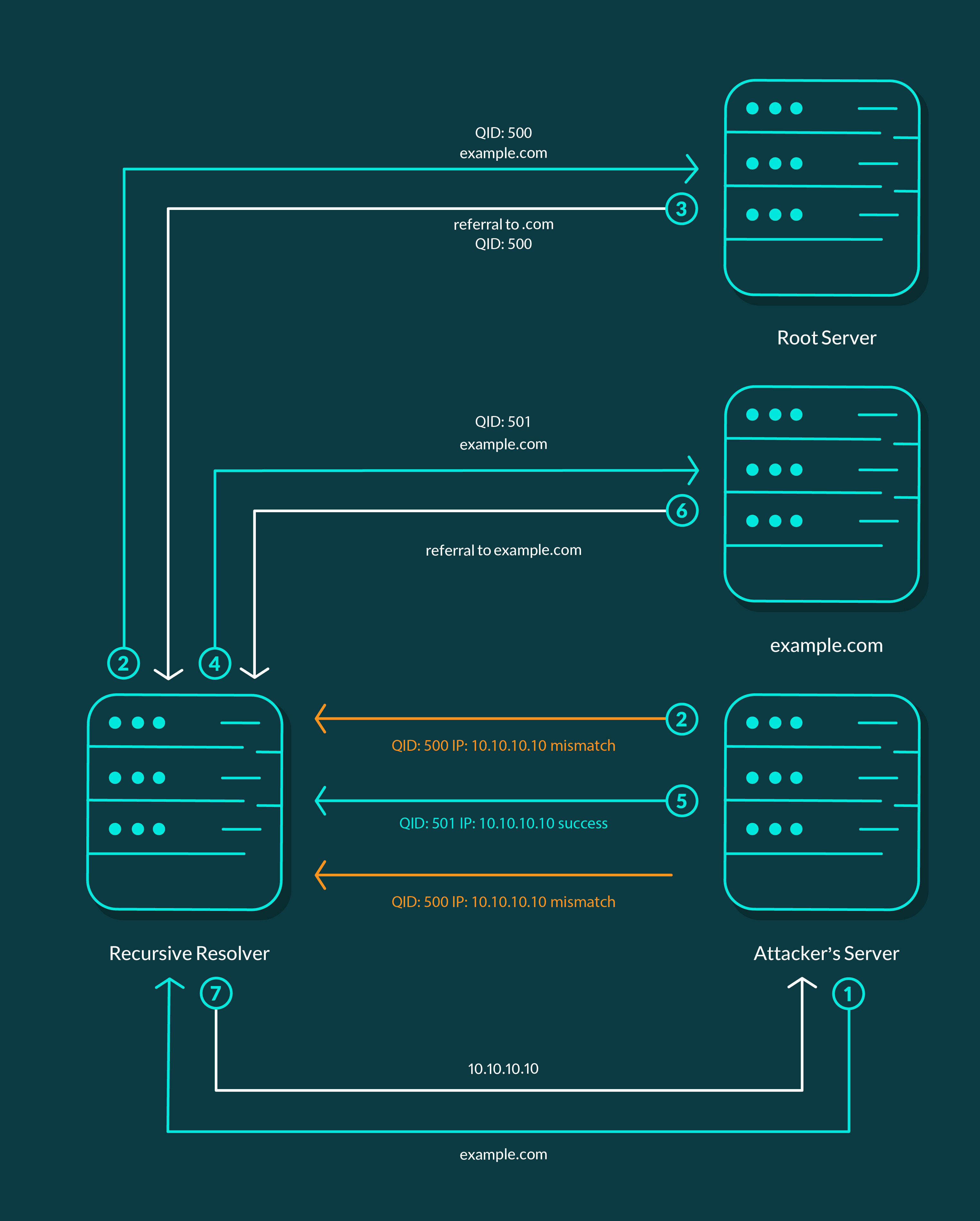
مهاجم ابتدا برای بهدست آوردن QID و شماره پورت، یک Host (تصور کنید یک وبسایت جعلی) در DNS server متعلق به خود ایجاد و سپس بهسمت Recursive Resolver، کوئری را برای دسترسی به این Host ارسال میکرد. چون در آن زمان سرورهای DNS، شماره پورتی تصادفی و خالی را در اختیار میگرفتند و برای تمام پیامهای بعدی که قرار بر ارسال آنها بود از همین شماره پورت بهعنوان شماره پورت مبدا در هِدر پیام UDP استفاده میکردند، و از سوی دیگر چون شماره QIDها بهشکل متوالی افزایش پیدا میکردند، مهاجم تنها با شنود ترافیک DNS جاری شده بهسمت سرور خود میتوانست بهراحتی به این دو مورد دست پیدا کند.
مرحلهی بعد، سمی کردن رکورد مربوط به Host مورد حمله در DNS سرور Recursive Resolver بود. ابتدا مهاجم با ارسال Query، از Recursive Resolver آدرس IP مربوط به Host مورد نظر را پرسوجو میکرد. Recursive Resolver نیز برای پیدا کردن آدرس آن Host (البته اگر آن را در Cache خود ذخیره نداشت) به سراغ Root Server میرفت. همزمان با اینکه Recursive Resolver پیام Query را برای یافتن آدرس IP دامنهی مورد نظر برای Root Server ارسال میکرد، مهاجم نیز شروع به ارسال پیدرپی responseهایی با آدرس IP جعلی و QIDهایی در بازهی QID بهدست آورده، میکرد.
نخستین QID که با QID مربوط به Query ارسال شده مطابقت پیدا میکرد، Recursive Server همان را بهعنوان پاسخ درست میپذیرفت و در Cache خود ذخیره میکرد و حتا اگر پس از آن سرور اصلی مربوط به آن Host نیز، پاسخ درست را ارسال میکرد، آن پاسخ دیگر پذیرفته نمیشد.
تصویر زیر بیانگر اتفاقاتی است که گفته شد.
شاید این حمله به گفتار ساده باشد اما در حقیقت دارای پیچیدگیهای بسیاری است:
- نخست آنکه دامنهی مورد حمله نباید در Cache سرور Recursive موجود باشد وگرنه آنچه در بالا توضیح داده شد، رخ نمیدهد و Recursive Resolver بیدرنگ با دریافت Query از جانب سیستم مهاجم، آدرس IP که در Cache خود ذخیره دارد را برای آن ارسال میکند.
- دوم آن که مهاجم باید توانایی حدس زدن QID را داشته باشد.
- مورد سوم آنکه، سیستم مهاجم باید سرعت عملی بیشتر از ارتباط میان Recursive Resolver و Root Server داشته باشد تا بتواند پاسخی با QID مورد انتظار در Recursive Resolver را سریعتر از Name Server اصلی ارسال کند.
این مشکل نخستینبار بهوسیلهی Computer Science Research Group (CSRG) در دانشگاه Berkeley در سال ۱۹۸۹ کشف شد و از آن جایی دارای اهمیت بود که دو برنامهی مشهور UNIX در آن زمان (rsh و rlogin) از DNS برای احراز هویت کاربرانی که قصد ریموت زدن به آنها را داشتند، استفاده میکردند. این دو برنامه به آدرس IP نگاهی میانداختند و متناسب با آن، hostname را بهدست میآوردند و بدون هیچ پرسش اضافهتری که آیا این کاربر معتبر است یا نه، آن را میپذیرفتند. پس یک مهاجم بهراحتی میتوانست با یک کاربر جعلی به این برنامهها دسترسی پیدا کند. CSRG برای حل این مشکل، Query رکورد PTR علاوهبر رکورد A را پیشنهاد کرد. اما این روش نیز با DNS cache poisoning قابل دور زدن بود.
راهحل دیگر استفاده از Transaction IDهای تصادفی برای BIND بود. اما بیشتر راهحلهای پیشنهادی برای امنسازی DNS چندان هم خوب به نظر نمیرسیدند و نیاز به یک روش بهتر، همچنان احساس میشد. در سال ۱۹۹۷ نهاد IETF نخستین RFC (2065) را در رابطه با راهحلی بهتر برای امنسازی DNS ارایه کرد. این راهحل Domain Name System Security Extensions (DNSSEC) نام داشت اما جز برای محققانی که بهخوبی بر مشکلات بسیار DNS آگاهی داشتند، مورد استقبال قرار نگرفت و بنا به هر دلیلی، جدی قلمداد نشد.
باگ Kaminsky
در سال ۲۰۰۸، محققی بهنام Dan Kaminsky اعلام کرد که شیوهی جدیدی از حملات Cache Poisoning را کشف کرده که بسیار بدتر از انواع قبلی است.
همانطورکه در بخش قبل توضیح داده شد، در حملهی Cache Poisoning مهاجم قادر بود تا با سمی کردن رکورد مربوط به Host مورد حمله در Cache مربوط به Recursive Server، کاری کند که درخواست کاربران برای دسترسی به آن Host، بهسمت سرور جعلی او منتقل شوند. اما Kaminsky کشف کرد که مهاجم میتواند یک گام فراتر رود و بهجای سمی کردن رکورد مربوط به یک Host، کاری کند که تمام درخواستهای مربوط به یک دامنهی خاص، سمی شوند. برای نمونه فرض کنید در تصویر بالا تمام درخواستهایی که مربوط به دامنهی example.com هستند (example.com، example2.com و …) بهسمت سرور جعلی مهاجم منتقل شوند.
در این حمله مهاجم بهجای هدف قرار دادن رکورد A در پیام DNS، به سراغ Authority رکوردها میرود و اینگونه ادعا میکند که name server مورد درخواست نیست اما از آن اطلاع دارد و میتواند پاسخ درخواستهای مربوط به این name server را بدهد. به بیان بهتر خود را بهعنوان یک Authoritative name server جا میزند. به این ترتیب هر درخواستی که به دست Recursive Resolver برسد که مربوط به دامنهی هدف باشد، بهسمت مهاجم ارسال میشود.
پیدا شدن این باگ جامعهی اینترنت را مجاب به یافتن راهی برای حل این مشکل کرد. راهحل پیشنهادی، افزایش سایز QID از ۱۶ بیت به ۳۲ بیت، همچنین استفاده از شماره پورتهای تصادفی برای هر پیام DNS بهجای یک پورت UDP یکسان برای همهی پیامها بود. این راهحلها هر چند سبب سختتر شدن کار مهاجمان برای انجام این حمله میشدند اما آن را به یک امر ناممکن مبدل نمیساختند. پس باز هم نیاز به روشی برای امنتر کردن DNS همچنان احساس میشد.
تمام این موارد سبب شدند تا ضرورت توسعه و استفاده از DNSSEC که پیشتر بهوسیلهی IETF معرفی شده بود، بیش از پیش احساس شود. برای آشنایی با شیوهی عملکرد DNSSEC میتوانید مقالهی «DNSSEC چیست و چگونه عمل میکند» را مطالعه کنید.